
Custom Se/Deserializer 문제점
Apache kafka serialization에 보면 Serializer & Deserializer 역할을 가진 인터페이스를 Serde 가 정의되어있다.
직렬화/역직렬화를 하는 클래스를 Serde 라고 지칭하겠다.
public interface Serde<T> extends Closeable {
// ..
Serializer<T> serializer();
Deserializer<T> deserializer();
}
Avro 란
JSON 으로 정의된 Schema
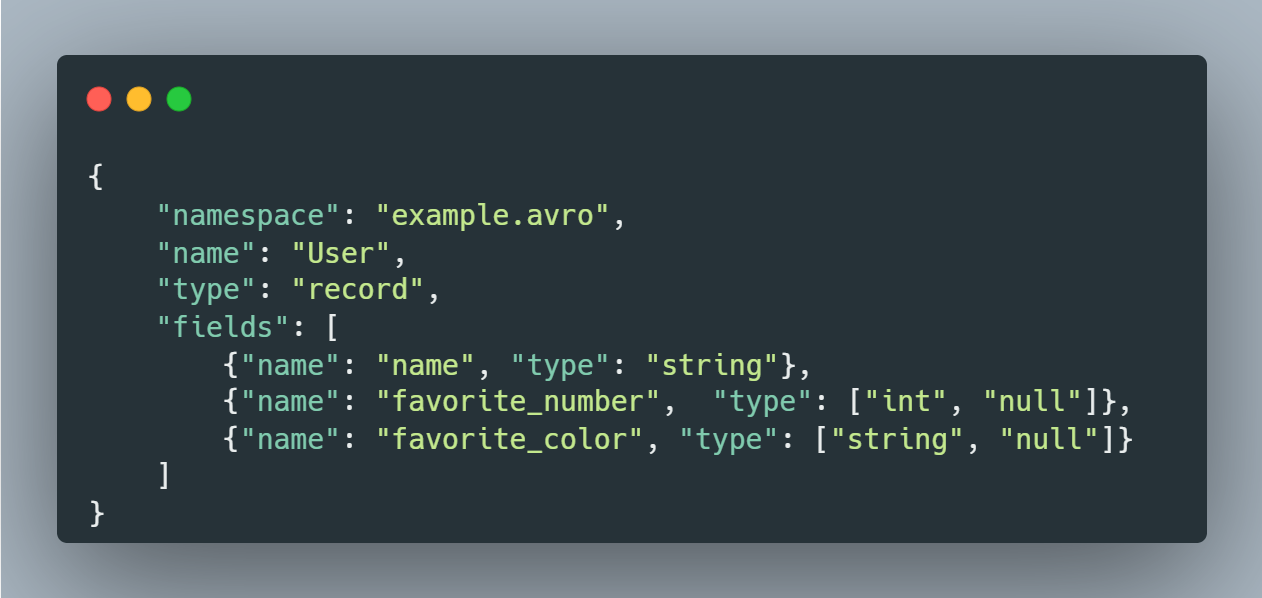
Avro 기존 커스텀 Serdes 의 문제를 해결했나
- Registry 지원으로 스키마 변경 지원
- Avro 스키마에 맞는 Serde 구현체 코드 자동생성
Avro Class 로 불린다. - 애플리케이션 변경을 요구하지 않음
Kafka Avro Serdes 는
POJO 객체가 아닌 Avro 객체 직렬화만 지원한다.
따라서 Avro 클래스 생성이 필요하다.
Avro Se/Deserialize 지원 방식
Serialize
Avro 직렬화는 JSON format 또는 Binary (byte array) 만 지원한다.
성능 측면에서는 Binary 타입이 유리하나, 디버깅과 웹기반 개발인 경우 애용되는 JSON 을 사용할 수도 있다.
Avro specifies two serialization encodings: binary and JSON.
Most applications will use the binary encoding, as it is smaller and faster.
But, for debugging and web-based applications, the JSON encoding may sometimes be appropriate.
- 출처: apache avro 공식 문서
UserAvro 직렬화/역직렬화 예제
user.avsc
build.gradle 설정
Avro 클래스 파일을 생성을 위한 패키지와 관련 설정

Custom Serde (Serializer & Deserializer) 구현
이렇게 직렬화/역직렬화를 위한 커스텀 Serde 클래스를 구현함으로써 Producer & Consumer 에서 곧바로 Avro 로 생성된 클래스에 대해 직렬화/역직렬화가 가능해진다.
Json Serialize 내부 구현 뜯어보기

JsonEncoder 구현체에서 핵심 기능을 하는 멤버 필드는 JsonGenerator 타입인 out 이다.
JsonEncoder(Schema sc, OutputStream out) throws IOException {
this(sc, getJsonGenerator(out, false));
}
private static JsonGenerator getJsonGenerator(OutputStream out, boolean pretty) throws IOException {
Objects.requireNonNull(out, "OutputStream cannot be null");
JsonGenerator g = new JsonFactory().createGenerator(out, JsonEncoding.UTF8);
// ..
return g;
}JsonGenerator는 JackSon 라이브러리에서 사용하는 추상클래스로 실제 구현체는 보통 utf8JsonGenerator 가 된다.
이 구현체는 자체적인 버퍼를 가지고 있다.
UserSerializer 코드 중 실제로 Byte 형태로 데이터를 쓰는 코드 부분을 집중해서 파헤쳐보자.

- userWriter.write() 를 호출하면 jsonGenerator.write() 메소드에 의해 실제 데이터를 버퍼에 바이트로 쓴다.
- jsonEncoder.flush() 시 jsonGenerator 가 앞서 썼던 내장된 버퍼의 데이터를 byteOutputStream 으로 흘려보낸다.
- byteOutputStream 을 읽어 데이터를 반환한다.
위 절차를 도식화해보면 다음과 같다.

테스트용 메인 클래스
메시지를 발행하고
구독하여 확인한다.
apache.kafka.clients.consumer.internals.ConsumerCoordinator -- [Consumer clientId=consumer-user-consumer-group-1, groupId=user-consumer-group] Setting offset for partition user-source-topic-0 to the committed offset FetchPosition{offset=9, offsetEpoch=Optional[0], currentLeader=LeaderAndEpoch{leader=Optional[localhost:9092 (id: 1 rack: null)], epoch=0}}
key: null value: {"name": "jayce", "favorite_number": 7, "favorite_color": "Red"}
Schema Registry Pattern
Kafka 에서 Avro 스키마를 관리하는 전략 패턴이다.
Avro 의 장점인 스키마 - 애플리케이션간 의존성을 줄여 스키마의 변경을 자유롭게한다.

절차
- Producer 의 Serializer 가 스키마 ID 및 스키마를 Schema Registry 에 전달
- Serializer 가 데이터 serialize 시 스키마 ID를 기록
- Kafka broker Validation (Optional)
- Consumer 의 Deserializer 가 메시지 구독 수신
- (4.)에서 받은 메시지에 담긴 스키마 ID를 읽고 Schema registry 로부터 해당 스키마 정보 조회
- (5.)에서 얻은 스키마 정보로 메시지 역직렬화
모든 메시지 발행/구독시 항상 Schema Registry API Call 및 유효성 검증을 하는 것은 지연을 발생시킬 수 있다.
Kafka Avro 는 스키마 레지스트리에 대한 캐싱 전략 및 Validation 활성화 옵션도 지원한다.
Schema Registry 를 사용하지 않는다면?
Custom Serde<T> 를 구현해야한다.
Generic Record vs Specific Record
Generic Record
Key-Value Map 과 다름없다.
어떤 데이터가 들어올지 모르는 범용성을 지원해야 하는 상황에서 쓴다.
보통 Schema 정보를 앞서 보인 스키마 레지스트리 없이 , 레코드에 직접 담는다.
레코드 크기가 방대해진다. 대신 런타임에 동적으로 스키마를 처리하기 때문에 유연하다.
Sepcific Record
사전에 정의한 Avro 스키마에 의해 컴파일된 Avro 클래스를 사용한다.
스키마 정의가 가능하다면 왠하면 이 방식을 사용하라.
유일한 단점은, Avro 스키마 변경시 어쨌든 Avro 클래스를 재생성해서 배포해야 한다는 점이다.
Questions
Q. Kafka Streams 에서 쓰는 Serde 랑 Apache Kafka native producer / consumer 가 같은 클래스 (Serde)를 쓰나?
A. 같다.
Q. 결국 Avro compiled file 로 Serde 구현체를 직접 구현하는 수밖에 없나? 구현체까지 자동으로 생성되게는 못하나?
A. Registry 를 사용하는 경우에는 io.confluent.KafkaAvroSerializer & KafkaAvroDeserializer + schema.registry.url 설정 조합으로 구현을 신경쓰지 않아도 된다.
반면, Registryless 경우 직접 구현체를 구현해야한다.
단, 이때 Serdes<T> 의 T가 Avro Class 로 제한될 뿐이다.
'기타 > Kafka' 카테고리의 다른 글
| [Kafka] Error: Failed to change permissions for the directory (1) | 2023.10.06 |
|---|---|
| Kafka 설정 방법 on Windows, Mac (0) | 2023.09.13 |